
اوراکل دیتاگارد
Oracle Data Guard
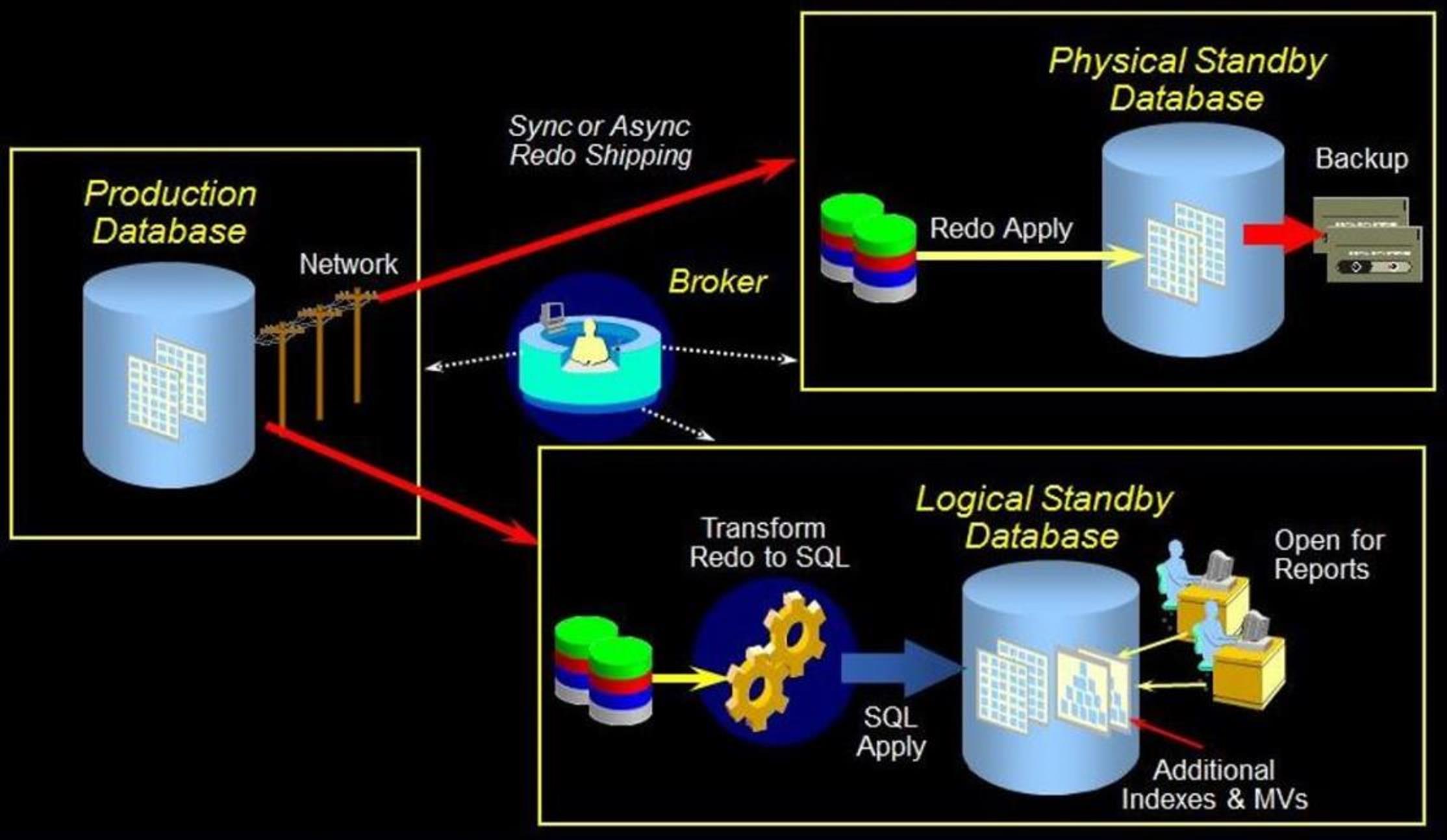
· Oracle Data Guard Overview
Oracle Data Guard یکی از optionهای Oracle Database Enterprise Edition است که نیاز به نصب و لایسنس جداگانه ندارد. (برای اولین بار در اوراکل 9i معرفی شد ).
پیکربندی دیتاگارد در واقع شامل دو بخش کلی میشود :
1- دیتابیس production یا primary : دیتابیسی که بوسیله بیشتر اپلیکیشن ها قابل دسترسی است . دیتابیس اصلی میتواند RAC باشد یا Single Instance .
2- دیتابیس یا دیتابیس های استندبای : در واقع یک کپی از دیتابیس اصلی است. همانند دیتابیس اصلی ، دیتابیس استندبای هم میتواند RAC باشد یا Single Instance . با استفاده از بکاپ دیتابیس اصلی شما میتوانید تا حداکثر 30 دیتابیس استندبای ( در 11gr2 ) ایجاد کنید.
دیتابیس ها در پیکربندی Data Guard با استفاده از Oracle Net به هم متصل میشوند . هیچ محدودیتی از این جهت که دیتابیس ها کجا میتوانند باشند وجود ندارد، مثلا شما میتوانید یک استندبای را روی همان سیستمی کانفیگ کنید که دیتابیس اصلی قرار دارد و استندبای دیگر را روی سیستمی که از لحاظ جغرافیایی در فاصله ای دورتر از دیتابیس اصلی قرار دارد.
مواردی که دیتاگارد خیلی روی آنها تمرکز دارد عبارتند از:
- Data Protection
- High Availability
- Disaster Recovery
یکی از مواردی که امروزه در خیلی از سایت ها اهمیت ویژه ای دارد مساله High Availability و کم کردن زمان Downtime است. به صورت کلی 2 مدل downtime ممکن است درسایت ما اتفاق بیفتد :
1- Unplanned downtime : خرابی های سخت افزاری یا نرم افزاری ، خطاهایی که در اثر اشتباه کاربر ممکن است اتفاق بیفتد و یا از دست دادن کل دیتاسنتر (natural disaster)
2- Planned downtime : اپلای کردن patchهای مختلف – انواع آپگریدهای سخت افزاری و نرم افزاری
دیتاگارد تا حد امکان میتواند به کاهش زمان downtime و بالا بردن high availability کمک کند. در مواردی شما میتوانید دیتاگارد را طوری پیکربندی کنید که data loss را به صفر برسانید.
· Types of Standby Databases
1- Physical Standby Database
2- Logical Standby Database
3- Snapshot Standby Database
· Physical Standby Database
یک کپی از دیتابیس اصلی است و از لحاظ ساختاری هیچ تفاوتی با دیتابیس اصلی ندارد و از طریق اپلای کردن redoهایی که از دیتابیس اصلی به استندبای منتقل شده اند با دیتابیس اصلی sync نگه داشته میشود.
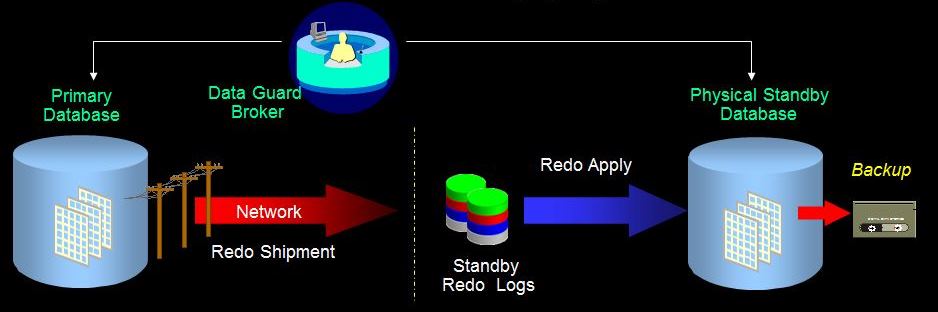
مزایای استفاده از physical standby database :
1- disaster recovery and high availability : اگر دیتابیس اصلی به هر دلیلی دچار مشکل شود ، میتوانید به دیتابیس استندبای failover کنید و از دیتابیس استندبای به عنوان دیتابیس اصلی استفاده کنید. (physical standby از لحاظ ساختاری هیچ تفاوتی با دیتابیس اصلی ندارد.)
2- data protection : در صورت رخداد بلایای پیش بینی نشده میتواند از data loss جلوگیری کند. همچنین از داده ها در برابر data corruption و خطاهای کاربر محافظت میکند.
- این نوع از استندبای همه data typeها را پشتیبانی میکند.
- این نوع از استندبای انواع دستورات DML و DDL که سمت دیتابیس اصلی زده میشود را پشتیبانی میکند.
3- Reduction in primary database workload : اگر شما لایسنس active data gurad را خریداری کرده باشید، میتوانید physical standby را open read only کنید و برای بکاپ گرفتن و گزارش گیری از آن استفاده کنید، که این موضوع منجر به کاهش بار در دیتابیس اصلی میشود.
4- Performance : تکنولوژی redo apply که برای sync نگه داشتن physical standby database با دیتابیس اصلی استفاده میشود ، تغییرات را با استفاده از پایین ترین سطح مکانیزم ریکاوری، اپلای میکند که این باعث میشود درگیر اجرای دستورات sql نشود و همین موضوع به بالا رفتن performance کمک میکند.
یک logical standby database در ابتدا از کپی دیتابیس اصلی ایجاد میشود ، اما بعدا ساختار آن میتواند تغییر داده شود. (از لحاظ منطقی شامل اطلاعاتی مشابه دیتابیس اصلی میباشد، اگرچه ساختار دیتا میتواند متفاوت باشد). از یک logical standby database میتوان به طور همزمان برای عملیات data protection و گزارش گیری استفاده کرد.
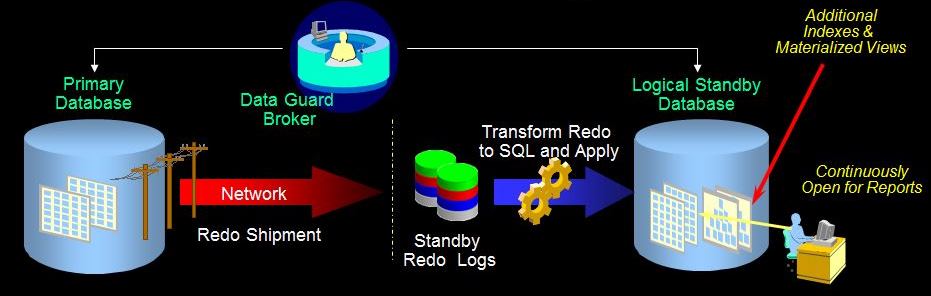
یک logical standby database از طریق apply کردن SQLها با دیتابیس اصلی sync نگه داشته میشود. در این نوع از استندبای redoهایی که از سمت دیتابیس اصلی به استندبای منتقل شده اند، به یک سری دستورات SQL تغییر شکل داده میشوند ( با استفاده از تکنولوژی logminer اینکار انجام میشود) سپس آن دستورات SQL درlogical standby اجرا میشوند.
هر چند که یک logical standby database در حالت عادی (open (read/write میباشد ولی جداول اصلی آن باید open read only باشند.
در یک logical standby database یک سری محدودیت هایی از لحاظ انواع data typeها ، نوع جداول ، و همچنین دستورات ddl و dml که در دیتابیس اصلی زده میشود وجود دارد.
· Snapshot Standby Database
بعضی مواقع شما میخواهید یک تستی (مثلا تست های مربوط به develop) را روی دیتابیس استندبای (که در واقع مشابه دیتابیس اصلی است) انجام دهید ولی نمیخواهید که دیتابیس استندبای با مشکل مواجه شود ، در چنین مواردی شما میتوانید Physical Standby را به Snapshot Standby تبدیل کنید ، وقتی که شما اینکار را انجام میدهید تمام وضعیت آن لحظه درسیستم شما ضبط میشود . از این زمان به بعد redoها از دیتابیس اصلی به استندبای منتقل میشوند ولی apply نمیشوند. بعد از اینکه کارهای مربوط به تست تمام شد ، میتوانید مجددا Snapshot Standby را به Physical Standby تبدیل کنید و بعد از آن تمام redoهایی که منتقل شده بودند apply میشوند.
· Data Guard Services
سه نوع سرویس مختلف در پیکربندی دیتاگارد وجود دارد :
1- Redo Transport Services : به طور کلی چند کار مهم را انجام میدهد:
- انتقال redoها از دیتابیس اصلی به استندبای
- برطرف کردن gapهایی که در اثر مشکلات شبکه ای بوجود می آیند.
- اگر یک archive redo log file در استندبای گم یا corrupt شود ، به صورت اتوماتیک سعی میشود که آن archive file از دیتابیس اصلی یا استندبای های دیگر جایگزین شود.
2- (Apply Services ( redo apply – sql apply : اپلای کردن redoها برای اینکه دیتابیس استندبای با دیتابیس اصلی sync نگه داشته شود. که اینکار درPhysical Standby با اپلای کردن redoها و در Logical Standby با اپلای کردن دستورات SQL انجام میشود.
3- (Role Transitions( switchover – failover : تغییر نقش دیتابیس از اصلی به استندبای و برعکس با استفاده از switch over وfailover.
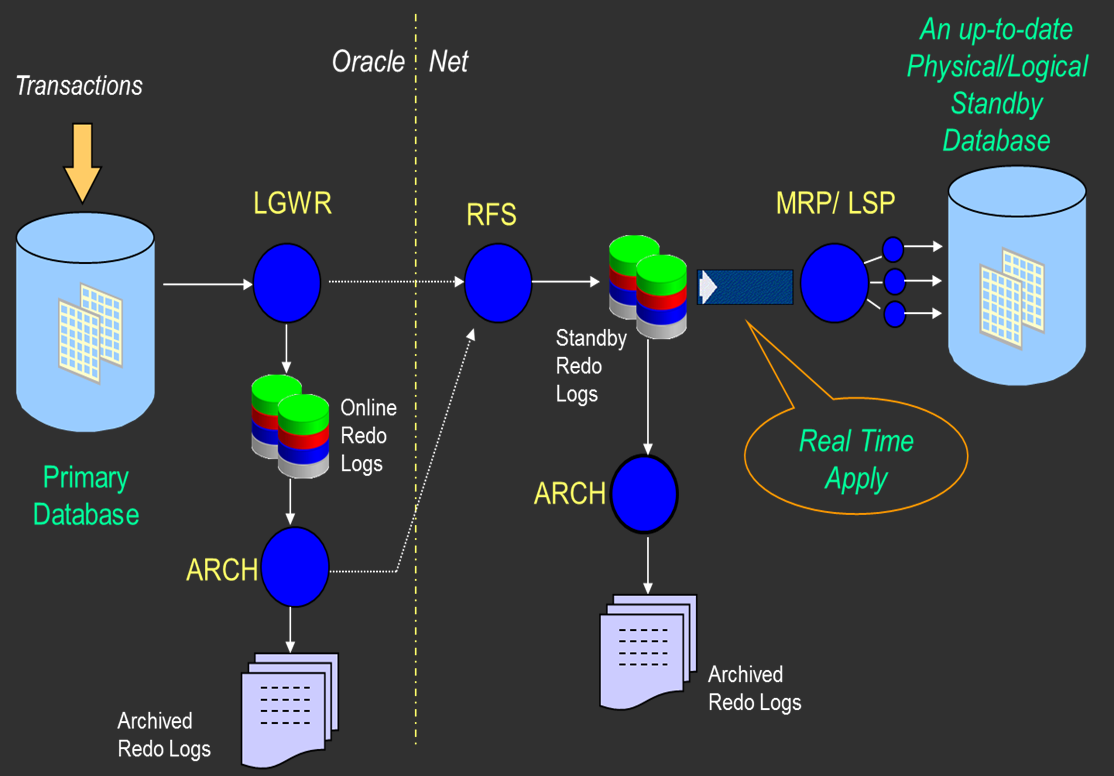
· Data Guard Architecture
در معماری دیتابیس وقتی که یک دستور DML یا DDL زده میشود ، اوراکل از روی آن دستور یک internal format ایجاد میکند که به اون internal format در اوراکل redo entry گفته میشود. این redo entry وقتی ایجاد شد در redo log buffer نوشته میشود.
LGWR background process در زمانهای مشخصی (3 ثانیه یک بار – وقتی 1/3 یا 1M از redo log buffer پر شود , ... ) فعال میشود و محتویات redo log buffer را روی redo log group که current است مینویسد.
وقتی دستور commit زده میشود ، از روی آن دستور commit هم مانند دستورات DML و DDL یک redo entry ایجاد میشود و در redo log buffer نوشته میشود . یکی دیگر از آن زمانهایی که LGWR فعال میشود ، زمان commit است. پس در حالت عادی ( وقتی استندبای نداریم ) ، وقتی کاربر دستور commit را میزند ، زمانی جواب commit را دریافت میکند که LGWR فعال شود و تمام محویات redo log buffer را در redo log file بنویسد.
وقتی دیتاگارد را configure میکنیم ، یک سری background process به مجموع background processهای دیتابیسهای اصلی و استندبای اضافه میشود :
- دیتابیس اصلی : ( LNS (LGWR Network Server
- دیتابیس استندبای :
(RFS ( Remote File Server
(MRP ( Managed Recovery Process
(LSP ( Logical Standby Process
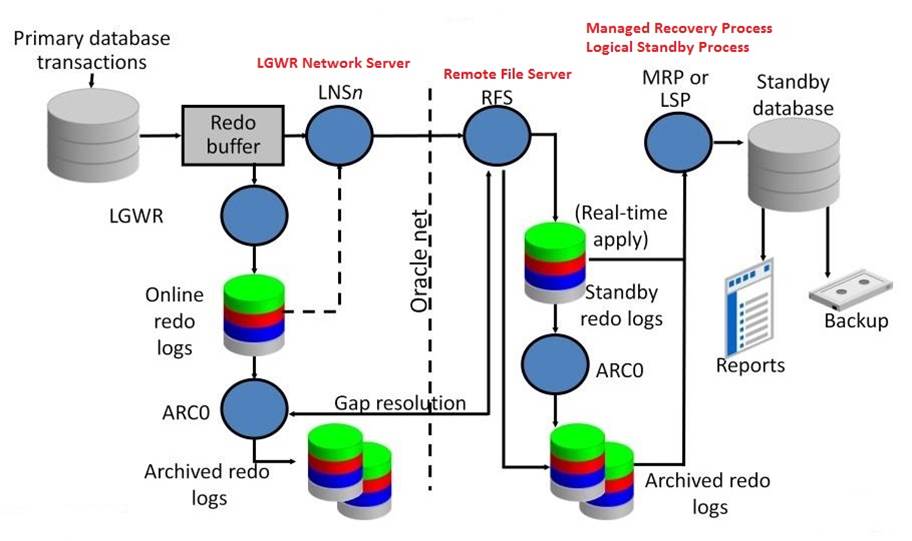
ما به 2 صورت میتوانیم دیتاگارد را configure کنیم : 1- sync ، 2- async
1- Sync : در این حالت ، وقتی کاربر دستور commit را میزند ، یک سری مراحل طی میشود تا پاسخی مبنی بر اینکه commit انجام شده است را دریافت کند.
- از روی دستورcommit یک redo entry ساخته میشود و در redo log buffer نوشته میشود ، LGWR فعال میشود و محتویات redo log buffer را به redo group منتقل میکند ، و منتظر پیغام LNS میماند.
- LNS هم محتویات redo log buffer را میخواند و از طریق Oracle Net به استندبای منتقل میکند ، سمت استندبای RFS کار دریافت redoها و نوشتن آنها در standby redo logها را انجام میدهد.
- وقتی کار RFS تمام شد، به LNS پیغامی مبنی بر اینکه کارش تمام شده برمیگرداند و LNS هم LGWR را از این موضوع با خبر میکند، بعد LGWR کاربر را از این موضوع که commit انجام شده است با خبر میکند.
این روش به عنوان روش zero data loss شناخته میشود. اگر از performance مربوط به network مطمئن باشید ، این روش میتواند روش کارآمدی باشد.
2- Async : در این حالت ، وقتی user دستور commit را میزند ، از روی دستورcommit یک redo entry ساخته میشود و در redo log buffer نوشته میشود ، LGWR فعال میشود و محتویات redo log buffer را به redo group منتقل میکند و بعد از اینکه این کار انجام شد ، کاربر پیغامی مبنی بر اینکه commit انجام شده است را دریافت میکند. یعنی در این حالت کاربر منتظر این نمی ماند که redoها به استندبای منتقل شوند و در standby redo log file نوشته شوند.
بعد از اینکه redoها به استندبای منتقل شدند ، background processهای MRP ( در physical standby) و یا LSP ( در logical standby ) کار apply کردن redoها را انجام میدهند که از این طریق دیتابیس اصلی با استندبای sync نگه داشته میشود.
· Automatic Gap Resolution
اگر ارتباط بین دیتابیس اصلی و استندبای به هر دلیلی دچار مشکل شود ، redoها نمیتوانند به استندبای منتقل شوند و یک gap اتفاق می افتد. وقتی که این ارتباط دوباره برقرار شد ، redo transport service به صورت اتوماتیک تشخیص میدهد که این gap از چه sequence تا چه sequence بوده است و آن redoها توسط back process ARC به استندبای منتقل میشوند.
در واقع وقتی یک gap اتفاق می افتد LNS نمیتواند redoها را به استندبای منتقل کند. بنابراین redoها در redo log file نوشته میشوند و توسط ARC آرشیو میشوند. وقتی این اتفاق میفتد ARC (که در سمت primary قرار دارد )، به طور مرتب در طی این زمان استندبای دیتابیس را ping میکند ، وقتی که استندبای دیتابیس به وضعیت عادی برگشت و مشکل حل شد ، ARC توسط RFS process از standby control file کوئری میگیرد تا بفهمد که آخرین redo که منتقل شده است شماره آن چند بوده ، و بعد از این ARC شروع به انتقال آن redoها میکند .
زمانی که طول میکشد تا آن gap که اتفاق افتاده است resolve شود به موارد مختلفی بستگی دارد ، مثلا به مقدار آن gap و performance لینک ارتباطی که بین دیتابیس اصلی و استندبای وجود دارد . redo transport service ، دو option را در اختیار ما میگذارد که اگر performance لینک ارتباطی ما پایین است میتوانیم از این 2 تا option استفاده کنیم :
1- redo transport compression : مشخص میکند که آرشیوها قبل از انتقال compress شوند.
(COMPRESSION (LOG_ARCHIVE_DEST_n
2- Parallel Redo Transport Network Sessions : فقط وقتی استفاده میشود که redo transport service بخواهد از ARCها استفاده کند برای انتقال آرشیوها. اگر مقدار آن به بیشتر از 1 ست شود ، redo transport service ، سمت دیتابیس اصلی بیشتر از یک ARCn راه اندازی میکند (برای انتقال آرشیوها به استندبای).
( MAX_CONNECTIONS ( LOG_ARCHIVE_DEST_n
· Data Guard Protection Mode
طبق توضیحات گفته شده در معماری دیتاگارد ، شما میتوانید دیتاگارد را در چند حالت مختلف configure کنید:· Real Time Apply
یکی از optionهای دیتاگارد است که برای اولین بار در اوراکل 10g معرفی شد. وقتی real time apply را فعال میکنید ، redoها مستقیما از standby redo logs خوانده و apply میشوند. اگر از real time apply استفاده نکنیم ، redoها از آرشیوها خوانده و apply میشوند.
n منابع
